34. Appendix C Verification Measures
This appendix provides specific information about the many verification statistics and measures that are computed by MET. These measures are categorized into measures for categorical (dichotomous) variables; measures for continuous variables; measures for probabilistic forecasts and measures for neighborhood methods. While the continuous, categorical, and probabilistic statistics are computed by both the Point-Stat and Grid-Stat tools, the neighborhood verification measures are only provided by the Grid-Stat tool.
34.1. Which statistics are the same, but with different names?
Statistics in MET |
Other names for the same statistic |
|---|---|
Probability of Detection |
Hit Rate |
Probability of False Detection |
False Alarm Rate (not Ratio) |
Critical Success Index |
Threat Score |
Gilbert Skill Score |
Equitable Threat Score |
Hanssen and Kuipers Discriminant |
True Skill Statistic, Pierce’s Skill Score |
Heidke Skill Score |
Cohen’s K |
Odds Ratio Skill Score |
Yule’s Q |
Mean Error |
Magnitude Bias |
Mean Error Squared (ME2) |
MSE by Mean Difference |
Bias Corrected MSE |
MSE by Pattern Variation |
MSESS |
Murphy’s MSESS |
Pearson Correlation |
Anomalous Pattern Correlation |
Anomaly Correlation |
Anomalous Correction |
Rank Histogram |
Talagrand Diagram |
Reliability Diagram |
Attributes Diagram |
Ignorance Score |
Logarithmic Scoring Rule |
34.2. MET Verification Measures for Categorical (Dichotomous) Variables
The verification statistics for dichotomous variables are formulated using a contingency table such as the one shown in Table 34.2. In this table f represents the forecasts and o represents the observations; the two possible forecast and observation values are represented by the values 0 and 1. The values in Table 34.2 are counts of the number of occurrences of the four possible combinations of forecasts and observations.
Forecast |
Observation |
Total |
|
|---|---|---|---|
o = 1 (e.g., “Yes”) |
o = 0 (e.g., “No”) |
||
f = 1 (e.g., “Yes”) |
\(\mathbf{n}_{11}\) |
\(\mathbf{n}_{10}\) |
\(\mathbf{n}_{1.} = \mathbf{n}_{11} + \mathbf{n}_{10}\) |
f = 0 (e.g., “No”) |
\(\mathbf{n}_{01}\) |
\(\mathbf{n}_{00}\) |
\(\mathbf{n}_{0.} = \mathbf{n}_{01} + \mathbf{n}_{00}\) |
Total |
\(\mathbf{n}_{.1} = \mathbf{n}_{11} + \mathbf{n}_{01}\) |
\(\mathbf{n}_{.0} = \mathbf{n}_{10} + \mathbf{n}_{00}\) |
\(T = \mathbf{n}_{11} + \mathbf{n}_{10} + \mathbf{n}_{01} + \mathbf{n}_{00}\) |
The counts, \(n_{11}, n_{10}, n_{01}, \text{and } n_{00},\) are sometimes called the “Hits”, “False alarms”, “Misses”, and “Correct rejections”, respectively.
By dividing the counts in the cells by the overall total, T, the joint proportions, \(\mathbf{p}_{11}, \mathbf{p}_{10}, \mathbf{p}_{01}, \text{and } \mathbf{p}_{00}\) can be computed. Note that \(\mathbf{p}_{11} + \mathbf{p}_{10} + \mathbf{p}_{01} + \mathbf{p}_{00} = 1.\) Similarly, if the counts are divided by the row (column) totals, conditional proportions, based on the forecasts (observations) can be computed. All of these combinations and the basic counts can be produced by the Point-Stat tool.
The values in Table 34.2 can also be used to compute the F, O, and H relative frequencies that are produced by the NCEP Verification System, and the Point-Stat tool provides an option to produce the statistics in this form. In terms of the other statistics computed by the Point-Stat tool, F is equivalent to the Mean Forecast; H is equivalent to POD; and O is equivalent to the Base Rate. All of these statistics are defined in the subsections below. The Point-Stat tool also provides the total number of observations, T.
The categorical verification measures produced by the Point-Stat and Grid-Stat tools are described in the following subsections. They are presented in the order shown in Table 11.2 through Table 11.5.
34.2.1. TOTAL
The total number of forecast-observation pairs, T.
34.2.2. Base Rate
Called “O_RATE” in FHO output Table 11.2
Called “BASER” in CTS output Table 11.4
The base rate is defined as \(\bar{o} = \frac{n_{11} + n_{01}}{T} = \frac{n_{.1}}{T}.\) This value is also known as the sample climatology, and is the relative frequency of occurrence of the event (i.e., o = 1). The base rate is equivalent to the “O” value produced by the NCEP Verification System.
34.2.3. Mean Forecast
Called “F_RATE” in FHO output Table 11.2
Called “FMEAN” in CTS output Table 11.4
The mean forecast value is defined as \(\bar{f} = \frac{n_{11} + n_{10}}{T} = \frac{n_{1.}}{T}.\)
This statistic is comparable to the base rate and is the relative frequency of occurrence of a forecast of the event (i.e., f = 1). The mean forecast is equivalent to the “F” value computed by the NCEP Verification System.
34.2.4. Accuracy
Called “ACC” in CTS output Table 11.4
Accuracy for a 2x2 contingency table is defined as
That is, it is the proportion of forecasts that were either hits or correct rejections - the fraction that were correct. Accuracy ranges from 0 to 1; a perfect forecast would have an accuracy value of 1. Accuracy should be used with caution, especially for rare events, because it can be strongly influenced by large values of \(\mathbf{n_{00}}\).
34.2.5. Frequency Bias
Called “FBIAS” in CTS output Table 11.4
Frequency Bias is the ratio of the total number of forecasts of an event to the total number of observations of the event. It is defined as
A “good” value of Frequency Bias is close to 1; a value greater than 1 indicates the event was forecasted too frequently and a value less than 1 indicates the event was not forecasted frequently enough.
34.2.6. H_RATE
Called “H_RATE” in FHO output Table 11.2
H_RATE is defined as
H_RATE is equivalent to the H value computed by the NCEP verification system. H_RATE ranges from 0 to 1; a perfect forecast would have H_RATE = 1.
34.2.7. Probability of Detection (POD)
Called “PODY” in CTS output Table 11.4
POD is defined as
It is the fraction of events that were correctly forecasted to occur. POD is also known as the hit rate. POD ranges from 0 to 1; a perfect forecast would have POD = 1.
34.2.8. Probability of False Detection (POFD)
Called “POFD” in CTS output Table 11.4
POFD is defined as
It is the proportion of non-events that were forecast to be events. POFD is also often called the False Alarm Rate. POFD ranges from 0 to 1; a perfect forecast would have POFD = 0.
34.2.9. Probability of Detection of the Non-Event (PODn)
Called “PODN” in CTS output Table 11.4
PODn is defined as
It is the proportion of non-events that were correctly forecasted to be non-events. Note that PODn = 1 - POFD. PODn ranges from 0 to 1. Like POD, a perfect forecast would have PODn = 1.
34.2.10. False Alarm Ratio (FAR)
Called “FAR” in CTS output Table 11.4
FAR is defined as
It is the proportion of forecasts of the event occurring for which the event did not occur. FAR ranges from 0 to 1; a perfect forecast would have FAR = 0.
34.2.11. Critical Success Index (CSI)
Called “CSI” in CTS output Table 11.4
CSI is defined as
It is the ratio of the number of times the event was correctly forecasted to occur to the number of times it was either forecasted or occurred. CSI ignores the “correct rejections” category (i.e., \(\mathbf{n_{00}}\)). CSI is also known as the Threat Score (TS). CSI can also be written as a nonlinear combination of POD and FAR, and is strongly related to Frequency Bias and the Base Rate.
34.2.12. Gilbert Skill Score (GSS)
Called “GSS” in CTS output Table 11.4
GSS is based on the CSI, corrected for the number of hits that would be expected by chance. In particular,
where
GSS is also known as the Equitable Threat Score (ETS). GSS values range from -1/3 to 1. A no-skill forecast would have GSS = 0; a perfect forecast would have GSS = 1.
34.2.13. Hanssen-Kuipers Discriminant (HK)
Called “HK” in CTS output Table 11.4
HK is defined as
More simply, HK = POD \(-\) POFD.
HK is also known as the True Skill Statistic (TSS) and less commonly (although perhaps more properly) as the Peirce Skill Score. HK measures the ability of the forecast to discriminate between (or correctly classify) events and non-events. HK values range between -1 and 1. A value of 0 indicates no skill; a perfect forecast would have HK = 1.
34.2.14. Heidke Skill Score (HSS)
Called “HSS” in CTS output Table 11.4 and “HSS” in MCTS output Table 11.9
HSS is a skill score based on Accuracy, where the Accuracy is compared to the number of correct forecasts that would be expected by chance. In particular,
where
Note that the C_2 value is calculated based on the data fields supplied by the user. Therefore, for C2 to appropriately represent a random forecast, a sufficiently large sized dataset of forecasts and observations would be needed.
HSS can range from minus infinity to 1. A perfect forecast would have HSS = 1.
34.2.15. Heidke Skill Score - Expected Correct (HSS_EC)
Called “HSS_EC” in CTS output Table 11.4 and MCTS output Table 11.9
HSS_EC calculates the HSS as described above, but with a C2 value based on a set expected chance (EC) value. Instead of C2 being calculated by the user’s dataset,
where EC is allowed to be prescribed by the user ranging from 0 to 1. By default the EC is set to 1 divided by the number of contingency table categories, e.g. EC is set to 0.33333 for a 3 category (tercile) forecast and 0.5 for a two category (binary) forecast.
HSS_EC can range from minus infinity to 1. A perfect forecast would have HSS_EC = 1.
34.2.16. Odds Ratio (OR)
Called “ODDS” in CTS output Table 11.4
OR measures the ratio of the odds of a forecast of the event being correct to the odds of a forecast of the event being wrong. OR is defined as
OR can range from 0 to \(\infty\). A perfect forecast would have a value of OR = infinity. OR is often expressed as the log Odds Ratio or as the Odds Ratio Skill Score (Stephenson, 2000).
34.2.17. Logarithm of the Odds Ratio (LODDS)
Called “LODDS” in CTS output Table 11.4
LODDS transforms the odds ratio via the logarithm, which tends to normalize the statistic for rare events (Stephenson, 2000). However, it can take values of \(\pm\infty\) when any of the contingency table counts is 0. LODDS is defined as \(\text{LODDS} = ln(OR)\).
34.2.18. Odds Ratio Skill Score (ORSS)
Called “ORSS” in CTS output Table 11.4
ORSS is a skill score based on the odds ratio. ORSS is defined as
ORSS is sometimes also referred to as Yule’s Q. (Stephenson, 2000).
34.2.19. Extreme Dependency Score (EDS)
Called “EDS” in CTS output Table 11.4
The extreme dependency score measures the association between forecast and observed rare events. EDS is defined as
EDS can range from -1 to 1, with 0 representing no skill. A perfect forecast would have a value of EDS = 1. EDS is independent of bias, so should be presented along with the frequency bias statistic (Stephenson et al., 2008).
34.2.20. Extreme Dependency Index (EDI)
Called “EDI” in CTS output Table 11.4
The extreme dependency index measures the association between forecast and observed rare events. EDI is defined as
where H and F are the Hit Rate and False Alarm Rate, respectively.
EDI can range from \(-\infty\) to 1, with 0 representing no skill. A perfect forecast would have a value of EDI = 1 (Ferro and Stephenson, 2011).
34.2.21. Symmetric Extreme Dependency Score (SEDS)
Called “SEDS” in CTS output Table 11.4
The symmetric extreme dependency score measures the association between forecast and observed rare events. SEDS is defined as
SEDS can range from \(-\infty\) to 1, with 0 representing no skill. A perfect forecast would have a value of SEDS = 1 (Ferro and Stephenson, 2011).
34.2.22. Symmetric Extremal Dependency Index (SEDI)
Called “SEDI” in CTS output Table 11.4
The symmetric extremal dependency index measures the association between forecast and observed rare events. SEDI is defined as
where \(H = \frac{n_{11}}{n_{11} + n_{01}}\) and \(F = \frac{n_{10}}{n_{00} + n_{10}}\) are the Hit Rate and False Alarm Rate, respectively.
SEDI can range from \(-\infty\) to 1, with 0 representing no skill. A perfect forecast would have a value of SEDI = 1. SEDI approaches 1 only as the forecast approaches perfection (Ferro and Stephenson, 2011).
34.2.23. Bias-Adjusted Gilbert Skill Score (BAGSS)
Called “BAGSS” in CTS output Table 11.4
BAGSS is based on the GSS, but is corrected as much as possible for forecast bias (Brill and Mesinger, 2009).
34.2.24. Economic Cost Loss Relative Value (ECLV)
Included in ECLV output Table 11.14
The Economic Cost Loss Relative Value (ECLV) applies a weighting to the contingency table counts to determine the relative value of a forecast based on user-specific information. The cost is incurred to protect against an undesirable outcome, whether that outcome occurs or not. No cost is incurred if no protection is undertaken. Then, if the event occurs, the user sustains a loss. If the event does not occur, there is neither a cost nor a loss. The maximum forecast value is achieved when the cost/loss ratio equals the climatological probability. When this occurs, the ECLV is equal to the Hanssen and Kuipers discriminant. The Economic Cost Loss Relative Value is defined differently depending on whether the cost / loss ratio is lower than the base rate or higher. The ECLV is a function of the cost / loss ratio (cl), the hit rate (h), the false alarm rate (f), the miss rate (m), and the base rate (b).
For cost / loss ratio below the base rate, the ECLV is defined as:
For cost / loss ratio above the base rate, the ECLV is defined as:
34.2.25. Stable Equitable Error in Probability Space (SEEPS)
Included in SEEPS output Table 11.22 and SEEPS_MPR output Table 11.21
The SEEPS scoring matrix (equation 15 from Rodwell et al, 2010) is:
In addition, Rodwell et al (2011) note that SEEPS can be written as the mean of two 2-category scores that individually assess the dry/light and light/heavy thresholds (Rodwell et al., 2011). Each of these scores is like 1 – HK, but written as:
where the word expected refers to the mean value deduced from the climatology, rather than the sample mean.
SEEPS scores are expected to lie between 0 and 1, with a perfect forecast having a value of 0. Individual values can be much larger than 1. Results can be presented as a skill score by using the value of 1 – SEEPS.
34.3. MET Verification Measures for Continuous Variables
For continuous variables, many verification measures are based on the forecast error (i.e., f - o). However, it also is of interest to investigate characteristics of the forecasts, and the observations, as well as their relationship. These concepts are consistent with the general framework for verification outlined by Murphy and Winkler, 1987. The statistics produced by MET for continuous forecasts represent this philosophy of verification, which focuses on a variety of aspects of performance rather than a single measure.
The verification measures currently evaluated by the Point-Stat tool are defined and described in the subsections below. In these definitions, f represents the forecasts, o represents the observation, and n is the number of forecast-observation pairs.
34.3.1. Mean Forecast
Called “FBAR” in CNT output Table 11.6
Called “FBAR” in SL1L2 output Table 11.15
The sample mean forecast, FBAR, is defined as \(\bar{f} = \frac{1}{n} \sum_{i=1}^{n} f_i\).
34.3.2. Mean Observation
Called “OBAR” in CNT output Table 11.6
Called “OBAR” in SL1L2 output Table 11.15
The sample mean observation is defined as \(\bar{o} = \frac{1}{n} \sum_{i=1}^{n} o_i\).
34.3.3. Forecast Standard Deviation
Called “FSTDEV” in CNT output Table 11.6
The sample variance of the forecasts is defined as
The forecast standard deviation is defined as \(s_f = \sqrt{s_f^2}\).
34.3.4. Observation Standard Deviation
Called “OSTDEV” in CNT output Table 11.6
The sample variance of the observations is defined as
The observed standard deviation is defined as \(s_o = \sqrt{s_o^2}\).
34.3.5. Pearson Correlation Coefficient
Called “PR_CORR” in CNT output Table 11.6
The Pearson correlation coefficient, r, measures the strength of linear association between the forecasts and observations. The Pearson correlation coefficient is defined as:
r can range between -1 and 1; a value of 1 indicates perfect correlation and a value of -1 indicates perfect negative correlation. A value of 0 indicates that the forecasts and observations are not correlated.
34.3.6. Spearman Rank Correlation Coefficient \((\rho_{s})\)
Called “SP_CORR” in CNT Table 11.6
The Spearman rank correlation coefficient (\(\rho_{s}\)) is a robust measure of association that is based on the ranks of the forecast and observed values rather than the actual values. That is, the forecast and observed samples are ordered from smallest to largest and rank values (from 1 to n, where n is the total number of pairs) are assigned. The pairs of forecast-observed ranks are then used to compute a correlation coefficient, analogous to the Pearson correlation coefficient, r.
A simpler formulation of the Spearman-rank correlation is based on differences between the each of the pairs of ranks (denoted as \(d_{i}\)):
Like r, the Spearman rank correlation coefficient ranges between -1 and 1; a value of 1 indicates perfect correlation and a value of -1 indicates perfect negative correlation. A value of 0 indicates that the forecasts and observations are not correlated.
34.3.7. Kendall’s Tau Statistic ( \(\tau\))
Called “KT_CORR” in CNT output Table 11.6
Kendall’s Tau statistic ( \(\tau\)) is a robust measure of the level of association between the forecast and observation pairs. It is defined as
where \(N_C\) is the number of “concordant” pairs and \(N_D\) is the number of “discordant” pairs. Concordant pairs are identified by comparing each pair with all other pairs in the sample; this can be done most easily by ordering all of the ( \(f_{i}, o_{i}\)) pairs according to \(f_{i}\), in which case the \(o_{i}\) values won’t necessarily be in order. The number of concordant matches of a particular pair with other pairs is computed by counting the number of pairs (with larger values) for which the value of \(o_i\) for the current pair is exceeded (that is, pairs for which the values of f and o are both larger than the value for the current pair). Once this is done, \(N_C\) is computed by summing the counts for all pairs. The total number of possible pairs is \(N_C\); thus, the number of discordant pairs is \(N_D\).
Like r and \(\rho_{s}\), Kendall’s Tau ( \(\tau\)) ranges between -1 and 1; a value of 1 indicates perfect association (concordance) and a value of -1 indicates perfect negative association. A value of 0 indicates that the forecasts and observations are not associated.
34.3.8. Mean Error (ME)
Called “ME” in CNT output Table 11.6 Called “ME_OERR”, “ME_GE_OBS”, and “ME_LT_OBS” in ECNT output Table 13.2
The Mean Error, ME, is a measure of overall bias for continuous variables; in particular ME = Bias. It is defined as
A perfect forecast has ME = 0.
34.3.9. Mean Error Squared (ME2)
Called “ME2” in CNT output Table 11.6
The Mean Error Squared, ME2, is provided to give a complete breakdown of MSE in terms of squared Bias plus estimated variance of the error, as detailed below in the section on BCMSE. It is defined as \(\text{ME2} = \text{ME}^2\).
A perfect forecast has ME2 = 0.
34.3.10. Multiplicative Bias
Called “MBIAS” in CNT output Table 11.6
Multiplicative bias is simply the ratio of the means of the forecasts and the observations: \(\text{MBIAS} = \bar{f} / \bar{o}\)
34.3.11. Mean-Squared Error (MSE)
Called “MSE” in CNT output Table 11.6
MSE measures the average squared error of the forecasts. Specifically, \(\text{MSE} = \frac{1}{n}\sum (f_{i} - o_{i})^{2}\).
34.3.12. Root-Mean-Squared Error (RMSE)
Called “RMSE” in CNT output Table 11.6 Called “RMSE” and “RMSE_OERR” in ECNT output Table 13.2
RMSE is simply the square root of the MSE, \(\text{RMSE} = \sqrt{\text{MSE}}\).
34.3.13. Scatter Index (SI)
Called “SI” in CNT output Table 11.6
SI is the ratio of the root mean squared error to the average observation value, \(\text{SI} = \text{RMSE} / \text{OBAR}\).
Smaller values of SI indicate better agreement between the model and observations (less scatter on scatter plot).
34.3.14. Standard Deviation of the Error
Called “ESTDEV” in CNT output Table 11.6
34.3.15. Bias-Corrected MSE
Called “BCMSE” in CNT output Table 11.6
MSE and RMSE are strongly impacted by large errors. They also are strongly impacted by large bias (ME) values. MSE and RMSE can range from 0 to infinity. A perfect forecast would have MSE = RMSE = 0.
MSE can be re-written as \(\text{MSE} = (\bar{f} - \bar{o})^{2} + s_{f}^{2} + s_{o}^{2} - 2s_{f} s_{o} r_{fo}\), where \(\bar{f} - \bar{o} = \text{ME}\) and \(s_f^2 + s_o^2 - 2 s_f s_o r_{fo}\) is the estimated variance of the error, \(s_{fo}^2\). Thus, \(\text{MSE} = \text{ME}^2 + s_{f-o}^2\). To understand the behavior of MSE, it is important to examine both of the terms of MSE, rather than examining MSE alone. Moreover, MSE can be strongly influenced by ME, as shown by this decomposition.
The standard deviation of the error, \(s_{f-o}\), is \(s_{f-o} = \sqrt{s_{f-o}^{2}} = \sqrt{s_{f}^{2} + s_{o}^{2} - 2 s_{f} s_{o} r_{fo}}\).
Note that the square of the standard deviation of the error (ESTDEV2) is sometimes called the “Bias-corrected MSE” (BCMSE) because it removes the effect of overall bias from the forecast-observation squared differences.
34.3.16. Mean Absolute Error (MAE)
Called “MAE” in CNT output Table 11.6 Called “MAE” and “MAE_OERR” in ECNT output Table 13.2
The Mean Absolute Error (MAE) is defined as \(\text{MAE} = \frac{1}{n} \sum|f_{i} - o_{i}|\).
MAE is less influenced by large errors and also does not depend on the mean error. A perfect forecast would have MAE = 0.
34.3.17. InterQuartile Range of the Errors (IQR)
Called “IQR” in CNT output Table 11.6
The InterQuartile Range of the Errors (IQR) is the difference between the 75th and 25th percentiles of the errors. It is defined as \(\text{IQR} = p_{75} (f_i - o_i) - p_{25} (f_i - o_i)\).
IQR is another estimate of spread, similar to standard error, but is less influenced by large errors and also does not depend on the mean error. A perfect forecast would have IQR = 0.
34.3.18. Median Absolute Deviation (MAD)
Called “MAD” in CNT output Table 11.6
The Median Absolute Deviation (MAD) is defined as \(\text{MAD} = \text{median}|f_i - o_i|\).
MAD is an estimate of spread, similar to standard error, but is less influenced by large errors and also does not depend on the mean error. A perfect forecast would have MAD = 0.
34.3.19. Mean Squared Error Skill Score
Called “MSESS” in CNT output Table 11.6
The Mean Squared Error Skill Score is one minus the ratio of the forecast MSE to some reference MSE, usually climatology. It is sometimes referred to as Murphy’s Mean Squared Error Skill Score.
34.3.20. Root-Mean-Squared Forecast Anomaly
Called “RMSFA” in CNT output Table 11.6
RMSFA is the square root of the average squared forecast anomaly. Specifically, \(\text{RMSFA} = \sqrt{\frac{1}{n} \sum(f_{i} - c_{i})^2}\).
34.3.21. Root-Mean-Squared Observation Anomaly
Called “RMSOA” in CNT output Table 11.6
RMSOA is the square root of the average squared observation anomaly. Specifically, \(\text{RMSOA} = \sqrt{\frac{1}{n} \sum(o_{i} - c_{i})^2}\).
34.3.22. Percentiles of the Errors
Called “E10”, “E25”, “E50”, “E75”, “E90” in CNT output Table 11.6
Percentiles of the errors provide more information about the distribution of errors than can be obtained from the mean and standard deviations of the errors. Percentiles are computed by ordering the errors from smallest to largest and computing the rank location of each percentile in the ordering, and matching the rank to the actual value. Percentiles can also be used to create box plots of the errors. In MET, the 0.10th, 0.25th, 0.50th, 0.75th, and 0.90th quantile values of the errors are computed.
34.3.23. Anomaly Correlation Coefficient
Called “ANOM_CORR” and “ANOM_CORR_UNCNTR” for centered and uncentered versions in CNT output Table 11.6
The anomaly correlation coefficient is equivalent to the Pearson correlation coefficient, except that both the forecasts and observations are first adjusted according to a climatology value. The anomaly is the difference between the individual forecast or observation and the typical situation, as measured by a climatology (c) of some variety. It measures the strength of linear association between the forecast anomalies and observed anomalies. The anomaly correlation coefficient is defined as:
The centered anomaly correlation coefficient (ANOM_CORR) which includes the mean error is defined as:
The uncentered anomaly correlation coefficient (ANOM_CORR_UNCNTR) which does not include the mean errors is defined as:
Anomaly correlation can range between -1 and 1; a value of 1 indicates perfect correlation and a value of -1 indicates perfect negative correlation. A value of 0 indicates that the forecast and observed anomalies are not correlated.
34.3.24. Partial Sums Lines (SL1L2, SAL1L2, VL1L2, VAL1L2)
Table 11.15, Table 11.16, Table 11.17, and Table 11.18
The SL1L2, SAL1L2, VL1L2, and VAL1L2 line types are used to store data summaries (e.g. partial sums) that can later be accumulated into verification statistics. These are divided according to scalar or vector summaries (S or V). The climate anomaly values (A) can be stored in place of the actuals, which is just a re-centering of the values around the climatological average. L1 and L2 refer to the L1 and L2 norms, the distance metrics commonly referred to as the “city block” and “Euclidean” distances. The city block is the absolute value of a distance while the Euclidean distance is the square root of the squared distance.
The partial sums can be accumulated over individual cases to produce statistics for a longer period without any loss of information because these sums are sufficient for resulting statistics such as RMSE, bias, correlation coefficient, and MAE (Mood et al., 1974). Thus, the individual errors need not be stored, all of the information relevant to calculation of statistics are contained in the sums. As an example, the sum of all data points and the sum of all squared data points (or equivalently, the sample mean and sample variance) are jointly sufficient for estimates of the Gaussian distribution mean and variance.
Minimally sufficient statistics are those that condense the data most, with no loss of information. Statistics based on L1 and L2 norms allow for good compression of information. Statistics based on other norms, such as order statistics, do not result in good compression of information. For this reason, statistics such as RMSE are often preferred to statistics such as the median absolute deviation. The partial sums are not sufficient for order statistics, such as the median or quartiles.
34.3.25. Scalar L1 and L2 Values
Called “FBAR”, “OBAR”, “FOBAR”, “FFBAR”, and “OOBAR” in SL1L2 output Table 11.15
These statistics are simply the 1st and 2nd moments of the forecasts, observations and errors:
Some of the other statistics for continuous forecasts (e.g., RMSE) can be derived from these moments.
34.3.26. Scalar Anomaly L1 and L2 Values
Called “FABAR”, “OABAR”, “FOABAR”, “FFABAR”, “OOABAR” in SAL1L2 output Table 11.16
Computation of these statistics requires a climatological value, c. These statistics are the 1st and 2nd moments of the scalar anomalies. The moments are defined as:
34.3.27. Vector L1 and L2 Values
Called “UFBAR”, “VFBAR”, “UOBAR”, “VOBAR”, “UVFOBAR”, “UVFFBAR”, “UVOOBAR” in VL1L2 output Table 11.17
These statistics are the moments for wind vector values, where u is the E-W wind component and v is the N-S wind component ( \(u_f\) is the forecast E-W wind component; \(u_o\) is the observed E-W wind component; \(v_f\) is the forecast N-S wind component; and \(v_o\) is the observed N-S wind component). The following measures are computed:
34.3.28. Vector Anomaly L1 and L2 Values
Called “UFABAR”, “VFABAR”, “UOABAR”, “VOABAR”, “UVFOABAR”, “UVFFABAR”, “UVOOABAR” in VAL1L2 output Table 11.18
These statistics require climatological values for the wind vector components, \(u_c \text{ and } v_c\). The measures are defined below:
34.3.29. Gradient Values
Called “TOTAL”, “FGBAR”, “OGBAR”, “MGBAR”, “EGBAR”, “S1”, “S1_OG”, and “FGOG_RATIO” in GRAD output Table 12.6
These statistics are only computed by the Grid-Stat tool and require vectors. Here \(\nabla\) is the gradient operator, which in this applications signifies the difference between adjacent grid points in both the grid-x and grid-y directions. TOTAL is the count of grid locations used in the calculations. The remaining measures are defined below:
where the weights are applied at each grid location, with values assigned according to the weight option specified in the configuration file. The components of the \(S1\) equation are as follows:
34.4. MET Verification Measures for Probabilistic Forecasts
The results of the probabilistic verification methods that are included in the Point-Stat, Grid-Stat, and Stat-Analysis tools are summarized using a variety of measures. MET treats probabilistic forecasts as categorical, divided into bins by user-defined thresholds between zero and one. For the categorical measures, if a forecast probability is specified in a formula, the midpoint value of the bin is used. These measures include the Brier Score (BS) with confidence bounds (Bradley, 2008); the joint distribution, calibration-refinement, likelihood-base rate (Wilks, 2011); and receiver operating characteristic information. Using these statistics, reliability and discrimination diagrams can be produced.
The verification statistics for probabilistic forecasts of dichotomous variables are formulated using a contingency table such as the one shown in Table 34.3. In this table f represents the forecasts and o represents the observations; the two possible forecast and observation values are represented by the values 0 and 1. The values in Table 34.3 are counts of the number of occurrences of all possible combinations of forecasts and observations.
Forecast |
Observation |
Total |
|
|---|---|---|---|
o = 1 (e.g., “Yes”) |
o = 0 (e.g., “No”) |
||
\(p_1\) = midpoint of (0 and threshold1) |
\(n_{11}\) |
\(n_{10}\) |
\(n_{1.} = n_{11} + n_{10}\) |
\(p_2\) = midpoint of (threshold1 and threshold2) |
\(n_{21}\) |
\(n_{20}\) |
\(n_{2.} = n_{21} + n_{20}\) |
… |
… |
… |
… |
\(p_j\) = midpoint of (threshold i and 1) |
n |
\(n_{i0}\) |
\(n_j = n_{j1} + n_{j0}\) |
Total |
\(n_{.1} = \sum n_{i1}\) |
\(n_{.0} = \sum n_{i0}\) |
\(\mathbf{T} = \sum n_i\) |
34.4.1. Reliability
Called “RELIABILITY” in PSTD output Table 11.11
A component of the Brier score. Reliability measures the average difference between forecast probability and average observed frequency. Ideally, this measure should be zero as larger numbers indicate larger differences. For example, on occasions when rain is forecast with 50% probability, it should actually rain half the time.
34.4.2. Resolution
Called “RESOLUTION” in PSTD output Table 11.11
A component of the Brier score that measures how well forecasts divide events into subsets with different outcomes. Larger values of resolution are best since it is desirable for event frequencies in the subsets to be different than the overall event frequency.
34.4.3. Uncertainty
Called “UNCERTAINTY” in PSTD output Table 11.11
A component of the Brier score. For probabilistic forecasts, uncertainty is a function only of the frequency of the event. It does not depend on the forecasts, thus there is no ideal or better value. Note that uncertainty is equivalent to the variance of the event occurrence.
34.4.4. Brier Score
Called “BRIER” in PSTD output Table 11.11
The Brier score is the mean squared probability error. In MET, the Brier Score (BS) is calculated from the nx2 contingency table via the following equation:
The equation you will most often see in references uses the individual probability forecasts ( \(\rho_{i}\)) and the corresponding observations ( \(o_{i}\)), and is given as \(\text{BS} = \frac{1}{T}\sum (p_i - o_i)^2\). This equation is equivalent when the midpoints of the binned probability values are used as the \(p_i\) .
BS can be partitioned into three terms: (1) reliability, (2) resolution, and (3) uncertainty (Murphy, 1987).
This score is sensitive to the base rate or climatological frequency of the event. Forecasts of rare events can have a good BS without having any actual skill. Since Brier score is a measure of error, smaller values are better.
34.4.5. Brier Skill Score (BSS)
Called “BSS” and “BSS_SMPL” in PSTD output Table 11.11
BSS is a skill score based on the Brier Scores of the forecast and a reference forecast, such as climatology. BSS is defined as
BSS is computed using the climatology specified in the configuration file while BSS_SMPL is computed using the sample climatology of the current set of observations.
34.4.6. OY_TP - Observed Yes Total Proportion
Called “OY_TP” in PJC output Table 11.12
This is the cell probability for row i, column j=1 (observed event), a part of the joint distribution (Wilks, 2011). Along with ON_TP, this set of measures provides information about the joint distribution of forecasts and events. There are no ideal or better values.
34.4.7. ON_TP - Observed No Total Proportion
Called “ON_TP” in PJC output Table 11.12
This is the cell probability for row i, column j=0 (observed non-event), a part of the joint distribution (Wilks, 2011). Along with OY_TP, this set of measures provides information about the joint distribution of forecasts and events. There are no ideal or better values.
34.4.8. Calibration
Called “CALIBRATION” in PJC output Table 11.12
Calibration is the conditional probability of an event given each probability forecast category (i.e. each row in the nx2 contingency table). This set of measures is paired with refinement in the calibration-refinement factorization discussed in Wilks, 2011. A well-calibrated forecast will have calibration values that are near the forecast probability. For example, a 50% probability of precipitation should ideally have a calibration value of 0.5. If the calibration value is higher, then the probability has been underestimated, and vice versa.
34.4.9. Refinement
Called “REFINEMENT” in PJC output Table 11.12
The relative frequency associated with each forecast probability, sometimes called the marginal distribution or row probability. This measure ignores the event outcome, and simply provides information about the frequency of forecasts for each probability category. This set of measures is paired with the calibration measures in the calibration-refinement factorization discussed by Wilks, 2011.
34.4.10. Likelihood
Called “LIKELIHOOD” in PJC output Table 11.12
Likelihood is the conditional probability for each forecast category (row) given an event and a component of the likelihood-base rate factorization; see Wilks, 2011 for details. This set of measures considers the distribution of forecasts for only the cases when events occur. Thus, as the forecast probability increases, so should the likelihood. For example, 10% probability of precipitation forecasts should have a much smaller likelihood value than 90% probability of precipitation forecasts.
Likelihood values are also used to create “discrimination” plots that compare the distribution of forecast values for events to the distribution of forecast values for non-events. These plots show how well the forecasts categorize events and non-events. The distribution of forecast values for non-events can be derived from the POFD values computed by MET for the user-specified thresholds.
34.4.11. Base Rate
Called “BASER” in PJC output Table 11.12
This is the probability of an event for each forecast category \(p_i\) (row), i.e. the conditional base rate. This set of measures is paired with likelihood in the likelihood-base rate factorization, see Wilks, 2011 for further information. This measure is calculated for each row of the contingency table. Ideally, the event should become more frequent as the probability forecast increases.
34.4.12. Reliability Diagram
The reliability diagram is a plot of the observed frequency of events versus the forecast probability of those events, with the range of forecast probabilities divided into categories.
The ideal forecast (i.e., one with perfect reliability) has conditional observed probabilities that are equivalent to the forecast probability, on average. On a reliability plot, this equivalence is represented by the one-to-one line (the solid line in the figure below). So, better forecasts are closer to the diagonal line and worse ones are farther away. The distance of each point from the diagonal gives the conditional bias. Points that lie below the diagonal line indicate over-forecasting; in other words, the forecast probabilities are too large. The forecast probabilities are too low when the points lie above the line. The reliability diagram is conditioned on the forecasts so it is often used in combination with the ROC, which is conditioned on the observations, to provide a “complete” representation of the performance of probabilistic forecasts.
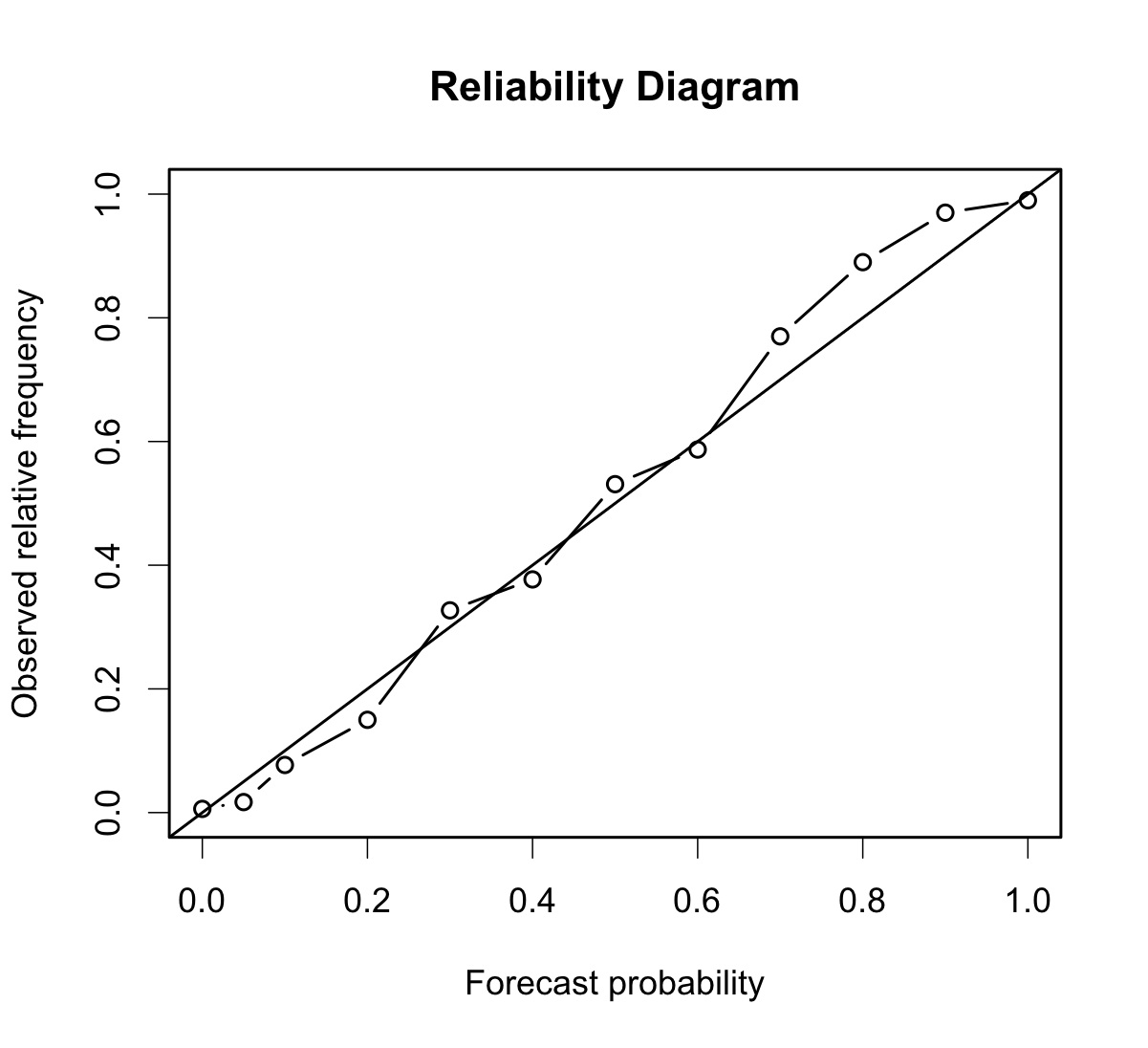
Figure 34.1 Example of Reliability Diagram
34.4.13. Receiver Operating Characteristic
MET produces hit rate (POD) and false alarm rate (POFD) values for each user-specified threshold. This information can be used to create a scatter plot of POFD vs. POD. When the points are connected, the plot is generally referred to as the receiver operating characteristic (ROC) curve (also called the “relative operating characteristic” curve). See the area under the ROC curve (AUC) entry for related information.
A ROC plot is shown for an example set of forecasts, with a solid line connecting the points for six user-specified thresholds (0.25, 0.35, 0.55, 0.65, 0.75, 0.85). The diagonal dashed line indicates no skill while the dash-dot line shows the ROC for a perfect forecast.
A ROC curve shows how well the forecast discriminates between two outcomes, so it is a measure of resolution. The ROC is invariant to linear transformations of the forecast, and is thus unaffected by bias. An unbiased (i.e., well-calibrated) forecast can have the same ROC as a biased forecast, though most would agree that an unbiased forecast is “better”. Since the ROC is conditioned on the observations, it is often paired with the reliability diagram, which is conditioned on the forecasts.
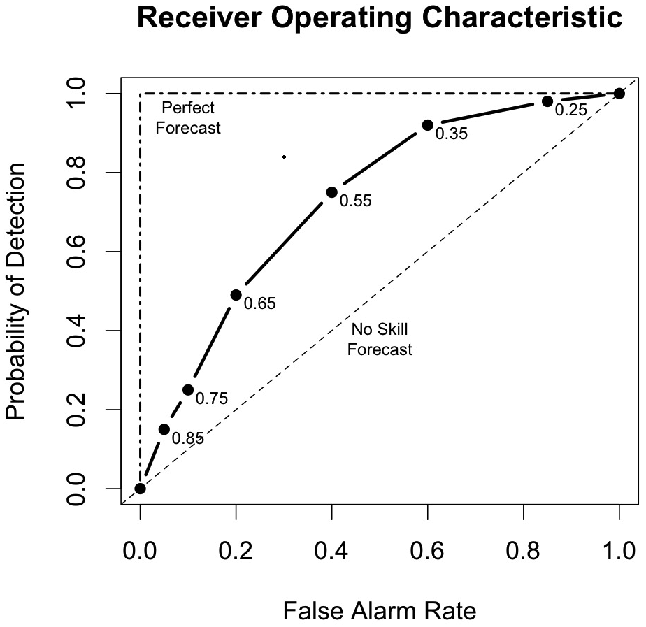
Figure 34.2 Example of ROC Curve
34.4.14. Area Under the ROC Curve (AUC)
Called “ROC_AUC” in PSTD output Table 11.11
The area under the receiver operating characteristic (ROC) curve is often used as a single summary measure. A larger AUC is better. A perfect forecast has AUC=1. Though the minimum value is 0, an AUC of 0.5 indicates no skill.
The area under the curve can be estimated in a variety of ways. In MET, the simplest trapezoid method is used to calculate the area. AUC is calculated from the series of hit rate (POD) and false alarm rate (POFD) values (see the ROC entry below) for each user-specified threshold.
34.5. MET Verification Measures for Ensemble Forecasts
34.5.1. RPS
Called “RPS” in RPS output Table 13.2
While the above probabilistic verification measures utilize dichotomous observations, the Ranked Probability Score (RPS, Epstein, 1969, Murphy, 1969) is the only probabilistic verification measure for discrete multiple-category events available in MET. It is assumed that the categories are ordinal as nominal categorical variables can be collapsed into sequences of binary predictands, which can in turn be evaluated with the above measures for dichotomous variables (Wilks, 2011). The RPS is the multi-category extension of the Brier score (Tödter and Ahrens, 2012), and is a proper score (Mason, 2008).
Let \(\text{J}\) be the number of categories, then both the forecast, \(\text{f} = (f_1,…,f_J)\), and observation, \(\text{o} = (o_1,…,o_J)\), are length-\(\text{J}\) vectors, where the components of \(\text{f}\) include the probabilities forecast for each category \(\text{1,…,J}\) and \(\text{o}\) contains 1 in the category that is realized and zero everywhere else. The cumulative forecasts, \(F_m\), and observations, \(O_m\), are defined to be:
\(F_m = \sum_{j=1}^m (f_j)\) and \(O_m = \sum_{j=1}^m (o_j), m = 1,…,J\).
To clarify, \(F_1 = f_1\) is the first component of \(F_m\), \(F_2 = f_1+f_2\), etc., and \(F_J = 1\). Similarly, if \(o_j = 1\) and \(i < j\), then \(O_i = 0\) and when \(i >= j\), \(O_i = 1\), and of course, \(O_J = 1\). Finally, the RPS is defined to be:
where \(BS_m\) is the Brier score for the m-th category (Tödter and Ahrens, 2012). Subsequently, the RPS lends itself to a decomposition into reliability, resolution and uncertainty components, noting that each component is aggregated over the different categories; these are written to the columns named “RPS_REL”, “RPS_RES” and “RPS_UNC” in RPS output Table 13.2.
34.5.2. CRPS
Called “CRPS”, “CRPSCL”, “CRPS_EMP”, “CRPS_EMP_FAIR” and “CRPSCL_EMP” in ECNT output Table 13.2
The continuous ranked probability score (CRPS) is the integral, over all possible thresholds, of the Brier scores (Gneiting et al., 2004). In MET, the CRPS is calculated two ways: using a normal distribution fit to the ensemble forecasts (CRPS and CRPSCL), and using the empirical ensemble distribution (CRPS_EMP and CRPSCL_EMP). The empirical ensemble CRPS can be adjusted (bias corrected) by subtracting 1/(2*m) times the mean absolute difference of the ensemble members, where m is the ensemble size. This is reported as a separate statistic called CRPS_EMP_FAIR. In some cases, use of other distributions would be better.
WARNING: The normal distribution is probably a good fit for temperature and pressure, and possibly a not horrible fit for winds. However, the normal approximation will not work on most precipitation forecasts and may fail for many other atmospheric variables.
Closed form expressions for the CRPS are difficult to define when using data rather than distribution functions. However, if a normal distribution can be assumed, then the following equation gives the CRPS for each individual observation (denoted by a lowercase crps) and the corresponding distribution of forecasts.
In this equation, the y represents the event threshold. The estimated mean and standard deviation of the ensemble forecasts ( \(\mu \text{ and } \sigma\)) are used as the parameters of the normal distribution. The values of the normal distribution are represented by the probability density function (PDF) denoted by \(\Phi\) and the cumulative distribution function (CDF), denoted in the above equation by \(\phi\).
The overall CRPS is calculated as the average of the individual measures. In equation form:
The score can be interpreted as a continuous version of the mean absolute error (MAE). Thus, the score is negatively oriented, so smaller is better. Further, similar to MAE, bias will inflate the CRPS. Thus, bias should also be calculated and considered when judging forecast quality using CRPS.
To calculate crps_emp_fair (bias adjusted, empirical ensemble CRPS) for each individual observation with m ensemble members:
The overall CRPS_EMP_FAIR is calculated as the average of the individual measures. In equation form:
34.5.3. Ensemble Mean Absolute Difference
Called “SPREAD_MD” in ECNT output Table 13.2
The ensemble mean absolute difference is an alternative measure of ensemble spread. It is computed for each individual observation (denoted by a lowercase spread_md) with m ensemble members:
The overall SPREAD_MD is calculated as the average of the individual measures. In equation form:
A perfect forecast would have ensemble mean absolute difference = 0.
34.5.4. CRPS Skill Score
Called “CRPSS” and “CRPSS_EMP” in ECNT output Table 13.2
The continuous ranked probability skill score (CRPSS) is similar to the MSESS and the BSS, in that it compares its namesake score to that of a reference forecast to produce a positively oriented score between 0 and 1.
For the normal distribution fit (CRPSS), the reference CRPS is computed using the climatological mean and standard deviation. For the empirical distribution (CRPSS_EMP), the reference CRPS is computed by sampling from the assumed normal climatological distribution defined by the mean and standard deviation.
34.5.5. Bias Ratio
Called “BIAS_RATIO” in ECNT output Table 13.2
The bias ratio (BIAS_RATIO) is computed when verifying an ensemble against gridded analyses or point observations. It is defined as the mean error (ME) of ensemble member values greater than or equal to the observation value to which they are matched divided by the absolute value of the mean error (ME) of ensemble member values less than the observation values.
A perfect forecast has ME = 0. Since BIAS_RATIO is computed as the high bias (ME_GE_OBS) divide by the absolute value of the low bias (ME_LT_OBS), a perfect forecast has BIAS_RATIO = 0/0, which is undefined. In practice, the high and low bias values are unlikely to be 0.
The range for BIAS_RATIO is 0 to infinity. A score of 1 indicates that the high and low biases are equal. A score greater than 1 indicates that the high bias is larger than the magnitude of the low bias. A score less than 1 indicates the opposite behavior.
34.5.6. IGN
Called “IGN” in ECNT output Table 13.2
The ignorance score (IGN) is the negative logarithm of a predictive probability density function (Gneiting et al., 2004). In MET, the IGN is calculated based on a normal approximation to the forecast distribution (i.e. a normal pdf is fit to the forecast values). This approximation may not be valid, especially for discontinuous forecasts like precipitation, and also for very skewed forecasts. For a single normal distribution N with parameters \(\mu \text{ and } \sigma\), the ignorance score is
Accumulation of the ignorance score for many forecasts is via the average of individual ignorance scores. This average ignorance score is the value output by the MET software. Like many error statistics, the IGN is negatively oriented, so smaller numbers indicate better forecasts.
34.5.7. PIT
Called “PIT” in ORANK output Table 13.7
The probability integral transform (PIT) is the analog of the rank histogram for a probability distribution forecast (Dawid, 1984). Its interpretation is the same as that of the verification rank histogram: Calibrated probabilistic forecasts yield PIT histograms that are flat, or uniform. Under-dispersed (not enough spread in the ensemble) forecasts have U-shaped PIT histograms while over-dispersed forecasts have bell-shaped histograms. In MET, the PIT calculation uses a normal distribution fit to the ensemble forecasts. In many cases, use of other distributions would be better.
34.5.8. Observation Error Logarithmic Scoring Rules
Called “IGN_CONV_OERR” and “IGN_CORR_OERR” in ECNT output Table 13.2
One approach that is used to take observation error into account in a summary measure is to add error to the forecast by a convolution with the observation model (e.g., Anderson, 1996; Hamill, 2001; Saetra et. al., 2004; Bröcker and Smith, 2007; Candille et al., 2007; Candille and Talagrand, 2008; Röpnack et al., 2013). Specifically, suppose \(y=x+w\), where \(y\) is the observed value, \(x\) is the true value, and \(w\) is the error. Then, if \(f\) is the density forecast for \(x\) and \(\nu\) is the observation model, then the implied density forecast for \(y\) is given by the convolution:
Ferro, 2017 gives the error-convolved version of the ignorance scoring rule (referred to therein as the error-convolved logarithmic scoring rule), which is proper under the model where \(w\sim N(0,c^2)\)) when the forecast for \(x\) is \(N(\mu,\sigma^2)\) with density function \(f\), by
Another approach to incorporation of observation uncertainty into a measure is the error-correction approach. The approach merely ensures that the scoring rule, \(s\), is unbiased for a scoring rule \(s_0\) if they have the same expected value. Ferro, 2017 gives the error-corrected ignorance scoring rule (which is also proposer when \(w\sim N(0,c^2)\)) as
The expected score for the error-convolved ignorance scoring rule typically differs from the expected score that would be achieved if there were no observation error. The error-corrected score, on the other hand, has the same expectation.
34.5.9. RANK
Called “RANK” in ORANK output Table 13.7
The rank of an observation, compared to all members of an ensemble forecast, is a measure of dispersion of the forecasts (Hamill, 2001). When ensemble forecasts possess the same amount of variability as the corresponding observations, then the rank of the observation will follow a discrete uniform distribution. Thus, a rank histogram will be approximately flat.
The rank histogram does not provide information about the accuracy of ensemble forecasts. Further, examination of “rank” only makes sense for ensembles of a fixed size. Thus, if ensemble members are occasionally unavailable, the rank histogram should not be used. The PIT may be used instead.
34.5.10. SPREAD
Called “SPREAD” in ECNT output Table 13.2
Called “SPREAD” in ORANK output Table 13.7
The ensemble spread for a single observation is the standard deviation of the ensemble member forecast values at that location. When verifying against point observations, these values are written to the SPREAD column of the Observation Rank (ORANK) line type. The ensemble spread for a spatial masking region is computed as the square root of the mean of the ensemble variance for all observations falling within that mask. These values are written to the SPREAD column of the Ensemble Continuous Statistics (ECNT) line type.
Note that prior to met-9.0.1, the ensemble spread of a spatial masking region was computed as the average of the spread values within that region. This algorithm was corrected in met-9.0.1 to average the ensemble variance values prior to computing the square root.
34.6. MET Verification Measures for Neighborhood Methods
The results of the neighborhood verification approaches that are included in the Grid-Stat tool are summarized using a variety of measures. These measures include the Fractions Skill Score (FSS) and the Fractions Brier Score (FBS). MET also computes traditional contingency table statistics for each combination of threshold and neighborhood window size.
The traditional contingency table statistics computed by the Grid-Stat neighborhood tool, and included in the NBRCTS output, are listed below:
Base Rate (called “BASER” in Table 12.3)
Mean Forecast (called “FMEAN” in Table 12.3)
Accuracy (called “ACC” in Table 12.3)
Frequency Bias (called “FBIAS” in Table 12.3)
Probability of Detection (called “PODY” in Table 12.3)
Probability of Detection of the non-event (called “PODN” in Table 12.3)
Probability of False Detection (called “POFD” in Table 12.3)
False Alarm Ratio (called “FAR” in Table 12.3)
Critical Success Index (called “CSI” in Table 12.3)
Gilbert Skill Score (called “GSS” in Table 12.3)
Hanssen-Kuipers Discriminant (called “HK” in Table 12.3)
Heidke Skill Score (called “HSS” in Table 12.3)
Odds Ratio (called “ODDS” in Table 12.3)
All of these measures are defined in Section 34.2.
In addition to these standard statistics, the neighborhood analysis provides additional continuous measures, the Fractions Brier Score and the Fractions Skill Score. For reference, the Asymptotic Fractions Skill Score and Uniform Fractions Skill Score are also calculated. These measures are defined here, but are explained in much greater detail in Ebert, 2008 and Roberts and Lean, 2008. Roberts and Lean, 2008 also present an application of the methodology.
34.6.1. Fractions Brier Score
Called “FBS” in NBRCNT output Table 12.5
The Fractions Brier Score (FBS) is defined as \(\text{FBS} = \frac{1}{N} \sum_N [\langle P_f\rangle_s - \langle P_o\rangle_s]^2\), where N is the number of neighborhoods; \(\langle P_{f} \rangle_{s}\) is the proportion of grid boxes within a forecast neighborhood where the prescribed threshold was exceeded (i.e., the proportion of grid boxes that have forecast events); and \(\langle P_{o}\rangle_{s}\) is the proportion of grid boxes within an observed neighborhood where the prescribed threshold was exceeded (i.e., the proportion of grid boxes that have observed events).
34.6.2. Fractions Skill Score
Called “FSS” in NBRCNT output Table 12.5
The Fractions Skill Score (FSS) is defined as
where the denominator represents the worst possible forecast (i.e., with no overlap between forecast and observed events). FSS ranges between 0 and 1, with 0 representing no overlap and 1 representing complete overlap between forecast and observed events, respectively.
34.6.3. Asymptotic Fractions Skill Score
Called “AFSS” in NBRCNT output Table 12.5
The Asymptotic Fractions Skill Score (AFSS) is a special case of the Fractions Skill score where the entire domain is used as the single neighborhood. This provides the user with information about the overall frequency bias of forecasts versus observations. The formula is the same as for FSS above, but with N=1 and the neighborhood size equal to the domain.
34.6.4. Uniform Fractions Skill Score
Called “UFSS” in NBRCNT output Table 12.5
The Uniform Fractions Skill Score (UFSS) is a reference statistic for the Fractions Skill score based on a uniform distribution of the total observed events across the grid. UFSS represents the FSS that would be obtained at the grid scale from a forecast with a fraction/probability equal to the total observed event proportion at every point. The formula is \(UFSS = (1 + f_o)/2\) (i.e., halfway between perfect skill and random forecast skill) where \(f_o\) is the total observed event proportion (i.e. observation rate).
34.6.5. Forecast Rate
Called “F_rate” in NBRCNT output Table 12.5
The overall proportion of grid points with forecast events to total grid points in the domain. The forecast rate will match the observation rate in unbiased forecasts.
34.6.6. Observation Rate
Called “O_rate” in NBRCNT output Table 12.5
The overall proportion of grid points with observed events to total grid points in the domain. The forecast rate will match the observation rate in unbiased forecasts. This quantity is sometimes referred to as the base rate.
34.7. MET Verification Measures for Distance Map Methods
The distance map statistics include Baddeley’s \(\Delta\) Metric, a statistic which is a true mathematical metric. The definition of a mathematical metric is included below.
A mathematical metric, \(m(A,B)\geq 0\), must have the following three properties:
Identity: \(m(A,B)=0\) if and only if \(A = B\).
Symmetry: \(m(A,B) = m(B,A)\)
Triangle inequality: \(m(A,C) \leq m(A,B) + m(B,C)\)
The first establishes that a perfect score is zero and that the only way to obtain a perfect score is if the two sets are identical according to the metric. The second requirement ensures that the order by which the two sets are evaluated will not change the result. The third property ensures that if C is closer to A than B is to A, then \(m(A,C) < m(A,B)\).
It has been argued in Gilleland, 2017 that the second property of symmetry is not necessarily an important quality to have for a summary measure for verification purposes because lack of symmetry allows for information about false alarms and misses.
The results of the distance map verification approaches that are included in the Grid-Stat tool are summarized using a variety of measures. These measures include Baddeley’s \(\Delta\) Metric, the Hausdorff Distance, the Mean-error Distance, Pratt’s Figure of Merit, and Zhu’s Measure. Their equations are listed below.
34.7.1. Baddeley’s \(\Delta\) Metric and Hausdorff Distance
Called “BADDELEY” and “HAUSDORFF” in the DMAP output Table 12.7
The Baddeley’s \(\Delta\) Metric is given by
where \(d(s,\cdot)\) is the distance map for the respective event area, \(w(\cdot)\) is an optional concave function (i.e., \(w( t + u) \leq w(t)+w(u))\) that is strictly increasing at zero with \(w(t)=0\) if and only if \(t=0\), N is the size of the domain, and p is a user chosen parameter for the \(L_{p}\) norm. The default choice of \(p = 2\) corresponds to a Euclidean average, \(p = 1\) is a simple average of the difference in distance maps, and the limiting case of \(p= \infty\) gives the maximum difference between the two distance maps and is called the Hausdorff distance, denoted as \(H(A,B)\), and is the metric that motivated the development of Baddeley’s \(\Delta\) metric. A typical choice, and the only available with MET, for \(w(\cdot) \text{ is } w(t)= \min\{t,c\}\), where c is a user-chosen constant with \(c = \infty\) meaning that \(w(\cdot)\) is not applied. This choice of \(w(\cdot)\) provides a cutoff for distances beyond the pre-specified amount given by c.
In terms of distance maps, Baddeley’s \(\Delta\) is the \(L_{p}\) norm of the top left panel in Figure 12.4 provided \(c= \infty\). If \(0<c< \infty\), then the distance maps in the bottom row of Figure 12.3 would be replaced by c wherever they would otherwise exceed c before calculating their absolute differences in the top left panel of Figure 12.4.
The range for BADDELEY and HAUSDORFF is 0 to infinity, with a score of 0 indicating a perfect forecast.
34.7.2. Mean-Error Distance
Called “MED_FO”, “MED_OF”, “MED_MIN”, “MED_MAX”, and “MED_MEAN” in the DMAP output Table 12.7
The mean-error distance (MED) is given by
where \(n_{B}\) is the number of non-zero grid points that fall in the event set B. That is, it is the average of the distance map for the event set A calculated only over those grid points that fall inside the event set B. It gives the average shortest-distance from every point in B to the nearest point in A.
Unlike Baddeley’s \(\Delta\) metric, the MED is not a mathematical metric because it fails the symmetry property. However, if a metric is desired, then any of the following modifications, which are metrics, can be employed instead, and all are available through MET.
From the distance map perspective, MED (A,B) is the average of the values in Figure 12.4 (top right), and MED (B,A) is the average of the values in Figure 12.4 (bottom left). Note that the average is only over the circular regions depicted in the figure.
The range for MED is 0 to infinity, with a score of 0 indicating a perfect forecast.
34.7.3. Pratt’s Figure of Merit
Called “FOM_FO”, “FOM_OF”, “FOM_MIN”, “FOM_MAX”, and “FOM_MEAN” in the DMAP output Table 12.7
Pratt’s Figure of Merit (FOM) is given by
where \(n_{A} \text{and } n_{B}\) are the number of events within event areas A and B, respectively, \(d(s,A)\) is the distance map related to the event area A, and \(\alpha\) is a user-defined scaling constant. The default, and usual choice, is \(\alpha = \frac{1}{9}\) when the distances of the distance map are normalized so that the smallest nonzero distance between grid point neighbors equals one. Clearly, FOM is not a metric because like MED, it is not symmetric. Like MED, MET computes the minimum, maximum, and average of FOM_FO and FOM_OF.
Note that \(d(s,A)\) in the denominator is summed only over the grid squares falling within the event set B. That is, it represents the circular area in the top right panel of Figure 12.4.
The range for FOM is 0 to 1, with a score of 1 indicating a perfect forecast.
34.7.4. Zhu’s Measure
Called “ZHU_FO”, “ZHU_OF”, “ZHU_MIN”, “ZHU_MAX”, and “ZHU_MEAN” in the DMAP output Table 12.7
Another measure incorporates the amount of actual overlap between the event sets across the fields in addition to the MED from above and was proposed by Zhu et al. (2011). Their main proposed measure was a comparative forecast performance measure of two competing forecasts against the same observation, which is not included here, but as defined is a true mathematical metric. They also proposed a similar measure of only the forecast against the observation, which is included in MET. It is simply
where MED (A,B) is as in the Mean-error distance, N is the total number of grid squares as in Baddeley’s \(\Delta\) metric, \(I_{F}(s) ((I_{O}(s))\) is the binary field derived from the forecast (observation), and \(\lambda\) is a user-chosen weight. The first term is just the RMSE of the binary forecast and observed fields, so it measures the average amount of overlap of event areas where zero would be a perfect score. It is not a metric because of the MED in the second term. A user might choose different weights depending on whether they want to emphasize the overlap or the MED terms more, but generally equal weight \((\lambda=\frac{1}{2})\) is sufficient. In Zhu et al (2011), they actually only consider \(Z(F,O)\) and not \(Z(O,F)\), but both are included in MET for the same reasons as argued with MED. Similar to MED, the average of these two directions (avg Z), as well as the min and max are also provided for convenience.
The range for ZHU is 0 to infinity, with a score of 0 indicating a perfect forecast.
34.7.5. \(G\) and \(G_\beta\)
Called “G” and “GBETA” in the DMAP output Table 12.7
See Section 12.2.9 for a description.
Let \(y = {y_1}{y_2}\) where \(y_1 = n_A + n_B - 2n_{AB}\), and \(y_2 = MED(A,B) \cdot n_B + MED(B,A) \cdot n_A\), with the mean-error distance (\(MED\)) as described above, and where \(n_{A}\), \(n_{B}\), and \(n_{AB}\) are the number of events within event areas A, B, and the intersection of A and B, respectively.
The \(G\) performance measure is given by
and the \(G_\beta\) performance measure is given by
where \(\beta > 0\) is a user-chosen parameter with a default value of \(n^2 / 2.0\) with \(n\) equal to the number of points in the domain. The square-root of \(G\) will give units of grid points, where \(y^{1/3}\) gives units of grid points squared.
The range for \(G_\beta\) is 0 to 1, with a score of 1 indicating a perfect forecast.
34.8. Calculating Percentiles
Several of the MET tools make use of percentiles in one way or another. Percentiles can be used as part of the internal computations of a tool, or can be written out as elements of some of the standard verification statistics. There are several widely-used conventions for calculating percentiles however, so in this section we describe how percentiles are calculated in MET.
The explanation makes use of the floor function. The floor of a real number x, denoted \(\lfloor x \rfloor\), is defined to be the greatest integer \(\leq x\). For example, \(\lfloor 3.01 \rfloor = 3, \lfloor 3.99 \rfloor = 3, \lfloor -3.01 \rfloor = -4, \lfloor -3.99 \rfloor = -4\). These examples show that the floor function does not simply round its argument to the nearest integer. Note also that \(\lfloor x \rfloor = x\) if and only if x is an integer.
Suppose now that we have a collection of N data points \(x_i \text{for } i = 0, 1, 2, \ldots, N - 1\). (Note that we’re using the C/C++ convention here, where array indices start at zero by default.) We will assume that the data are sorted in increasing (strictly speaking, nondecreasing) order, so that \(i \leq j \text{ implies } x_i \leq x_j\). Suppose also that we wish to calculate the t percentile of the data, where \(0 \leq t < 1\). For example, \(t = 0.25\) for the 25th percentile of the data. Define
Then the value p of the percentile is