8. Re-Formatting of Gridded Fields
Several MET tools exist for the purpose of reformatting gridded fields, and they are described in this section. These tools are represented by the reformatting column of MET flowchart depicted in Figure 1.1.
8.1. Pcp-Combine Tool
This section describes the Pcp-Combine tool which summarizes data across multiple input gridded data files and writes the results to a single NetCDF output file. It is often used to modify precipitation accumulation intervals in the forecast and/or observation datasets to make them comparable. However it can also be used to derive summary fields, such as daily min/max temperature or average precipitation rate.
The Pcp-Combine tool supports four types of commands (“sum”, “add”, “subtract”, and “derive”) which may be run on any gridded data files supported by MET.
The “sum” command is the default command and therefore specifying “-sum” on the command line is optional. Using the sum arguments described below, Pcp-Combine searches the input directories (“-pcpdir” option) for data that matches the requested time stamps and accumulation intervals. Pcp-Combine only considers files from the input data directory which match the specified regular expression (“-pcprx” option). While “sum” searches for matching data, all the other commands are run on the explicit set of input files specified.
The “add” command reads the requested data from the input data files and adds them together.
The “subtract” command reads the requested data from exactly two input files and computes their difference.
The “derive” command reads the requested data from the input data files and computes the requested summary fields.
By default, the Pcp-Combine tool processes data for APCP, the GRIB string for accumulated precipitation. When requesting data using time strings (i.e. [HH]MMSS), Pcp-Combine searches for accumulated precipitation for that accumulation interval. Alternatively, use the “-field” option to process fields other than APCP or for non-GRIB files. The “-field” option may be used multiple times to process multiple fields in a single run. Since the Pcp-Combine tool does not support automated regridding, all input data must be on the same grid. In general the input files should have the same initialization time unless the user has indicated that it should ignore the initialization time for the “sum” command. The “subtract” command produces a warning when the input initialization times differ or the subtraction results in a negative accumulation interval.
8.1.1. pcp_combine Usage
The usage statement for the Pcp-Combine tool is shown below:
Usage: pcp_combine
[-sum] sum_args |
-add input_files |
-subtract input_files |
-derive stat_list input_files
out_file
[-field string]
[-name list]
[-vld_thresh n]
[-log file]
[-v level]
[-compress level]
The arguments to pcp_combine vary depending on the run command. Listed below are the arguments for the sum command:
SUM_ARGS:
init_time
in_accum
valid_time
out_accum
out_file
[-pcpdir path]
[-pcprx reg_exp]
The add, subtract, and derive commands all require that the input files be explicitly listed:
INPUT_FILES:
file_1 config_str_1 ... file_n config_str_n |
file_1 ... file_n |
input_file_list
8.1.1.1. Required Arguments for the pcp_combine
The Pcp-Combine tool must be run with exactly one run command (-sum, -add, -subtract, or -derive) with the corresponding additional arguments.
The out_file argument indicates the name for the NetCDF file to be written.
8.1.1.2. Optional Arguments for pcp_combine
The -field string option defines the data to be extracted from the input files. Use this option when processing fields other than APCP or non-GRIB files. It can be used multiple times and output will be created for each. In general, the field string should include the name and level of the requested data and be enclosed in single quotes. It is processed as an inline configuration file and may also include data filtering, censoring, and conversion options. For example, use -field ‘name=”ACPCP”; level=”A6”; convert(x)=x/25.4;’ to read 6-hourly accumulated convective precipitation from a GRIB file and convert from millimeters to inches.
The -name list option is a comma-separated list of output variable names which override the default choices. If specified, the number of names must match the number of variables to be written to the output file.
The -vld_thresh n option overrides the default required ratio of valid data for at each grid point for an output value to be written. The default is 1.0.
The -log file option directs output and errors to the specified log file. All messages will be written to that file as well as standard out and error. Thus, users can save the messages without having to redirect the output on the command line. The default behavior is no log file.
The -v level option indicates the desired level of verbosity. The contents of “level” will override the default setting of 2. Setting the verbosity to 0 will make the tool run with no log messages, while increasing the verbosity above 1 will increase the amount of logging.
The -compress level option indicates the desired level of compression (deflate level) for NetCDF variables. The valid level is between 0 and 9. The value of “level” will override the default setting of 0 from the configuration file or the environment variable MET_NC_COMPRESS. Setting the compression level to 0 will make no compression for the NetCDF output. Lower number is for fast compression and higher number is for better compression.
8.1.1.3. Required Arguments for the pcp_combine Sum Command
The init_time argument, provided in YYYYMMDD[_HH[MMSS]] format, indicates the initialization time for model data to be summed. Only files found with this initialization time will be processed. If combining observation files, Stage II or Stage IV data for example, the initialization time is not applicable. Providing a string of all zeros (00000000_000000) indicates that all files, regardless of initialization time should be processed.
The in_accum argument, provided in HH[MMSS] format, indicates the accumulation interval of the model or observation gridded files to be processed. This value must be specified, since a model output file may contain multiple accumulation periods for precipitation in a single file. The argument indicates which accumulation period to extract.
The valid_time argument, in YYYYMMDD[_HH[MMSS]] format, indicates the desired valid time to which the accumulated precipitation is to be summed.
The out_accum argument, in HH[MMSS] format, indicates the desired total accumulation period to be summed.
8.1.1.4. Optional Arguments for pcp_combine Sum Command
The -pcpdir path option indicates the directories in which the input files reside. The contents of “path” will override the default setting. This option may be used multiple times and can accept multiple arguments, supporting the use of wildcards.
The -pcprx reg_exp option indicates the regular expression to be used in matching files in the search directories specified. The contents of “reg_exp” will override the default setting that matches all file names. If the search directories contain a large number of files, the user may specify that only a subset of those files be processed using a regular expression which will speed up the run time.
8.1.1.5. Required Arguments for the pcp_combine Derive Command
The “derive” run command must be followed by stat_list which is a comma-separated list of summary fields to be computed. The stat_list may be set to sum, min, max, range, mean, stdev, and vld_count for the sum, minimum, maximum, range (max-min), average, standard deviation, and valid data count fields, respectively.
8.1.1.6. Input Files for pcp_combine Add, Subtract, and Derive Commands
The input files for the add, subtract, and derive command can be specified in one of 3 ways:
Use file_1 config_str_1 … file_n config_str_n to specify the full path to each input file followed by a description of the data to be read from it. The config_str_i argument describing the data can be a set to a time string in HH[MMSS] format for accumulated precipitation or a full configuration string. For example, use ‘name=”TMP”; level=”P500”;’ to process temperature at 500mb.
Use file_1 … file_n to specify the list of input files to be processed on the command line. Rather than specifying a separate configuration string for each input file, the “-field” command line option is required to specify the data to be processed.
Use input_file_list to specify the name of an ASCII file which contains the paths for the gridded data files to be processed. As in the previous option, the “-field” command line option is required to specify the data to be processed.
An example of the pcp_combine calling sequence is presented below:
Example 1:
pcp_combine -sum \
20050807_000000 3 \
20050808_000000 24 \
sample_fcst.nc \
-pcpdir ../data/sample_fcst/2005080700
In Example 1, the Pcp-Combine tool will sum the values in model files initialized at 2005/08/07 00Z and containing 3-hourly accumulation intervals of precipitation. The requested valid time is 2005/08/08 00Z with a requested total accumulation interval of 24 hours. The output file is to be named sample_fcst.nc, and the Pcp-Combine tool is to search the directory indicated for the input files.
The Pcp-Combine tool will search for 8 files containing 3-hourly accumulation intervals which meet the criteria specified. It will write out a single NetCDF file containing that 24 hours of accumulation.
A second example of the pcp_combine calling sequence is presented below:
Example 2:
pcp_combine -sum \
00000000_000000 1 \
20050808_000000 24 \
sample_obs.nc \
-pcpdir ../data/sample_obs/ST2ml
Example 2 shows an example of using the Pcp-Combine tool to sum observation data. The init_time has been set to all zeros to indicate that when searching through the files in the precipitation directory, the initialization time should be ignored. The in_accum has been changed from 3 to 1 to indicate that the input observation files contain 1-hourly accumulations of precipitation. Lastly, -pcpdir provides a different directory to be searched for the input files.
The Pcp-Combine tool will search for 24 files containing 1-hourly accumulation intervals which meet the criteria specified. It will write out a single NetCDF file containing that 24 hours of accumulation.
Example 3:
pcp_combine -add input_pinterp.nc 'name="TT"; level="(0,*,*)";' tt_10.nc
This command would grab the first level of the TT variable from a pinterp NetCDF file and write it to the output tt_10.nc file.
Example 4:
pcp_combine -subtract 2022043018_48.grib2 'name="APCP"; level="A48";' 2022043018_36.grib2 'name="APCP"; level="A36";' sample_fcst.nc
The Pcp-Combine tool will subtract the 36 hour precipitation accumulations in the file 2022043018_36.grib2 (a 36hr forecast initialized at 2022-04-30 18Z) from the 48 hour accumulations in the file 2022043018_48.grib2 (a 48hr forecast from the same model cycle). This will produce the 12 hour accumulation amounts for the period in between the 36 and 48 hour forecasts. It will write out a single NetCDF file containing that 12 hours of accumulation.
8.1.2. pcp_combine Output
The output NetCDF files contain the requested accumulation intervals as well as information about the grid on which the data lie. That grid projection information will be parsed out and used by the MET statistics tools in subsequent steps. One may use NetCDF utilities such as ncdump or ncview to view the contents of the output file. Alternatively, the MET Plot-Data-Plane tool described in Section 30.1.3 may be run to create a PostScript image of the data.
Each NetCDF file generated by the Pcp-Combine tool contains the dimensions and variables shown in the following two tables.
Pcp_combine NetCDF dimensions |
|
|---|---|
NetCDF dimension |
Description |
lat |
Dimension of the latitude (i.e. Number of grid points in the North-South direction) |
lon |
Dimension of the longitude (i.e. Number of grid points in the East-West direction) |
Pcp_combine NetCDF variables |
||
|---|---|---|
NetCDF variable |
Dimension |
Description |
lat |
lat, lon |
Latitude value for each point in the grid |
lon |
lat, lon |
Longitude value for each point in the grid |
Name and level of the requested data or value of the -name option. |
lat, lon |
Data value (i.e. accumulated precipitation) for each point in the grid. The name of the variable describes the name and level and any derivation logic that was applied. |
8.2. Regrid-Data-Plane Tool
This section contains a description of running the Regrid-Data-Plane tool. This tool may be run to read data from any gridded file MET supports, interpolate to a user-specified grid, and writes the field(s) out in NetCDF format. The user may specify the method of interpolation used for regridding as well as which fields to regrid. This tool is particularly useful when dealing with GRIB2 and NetCDF input files that need to be regridded. For GRIB1 files, it has also been tested for compatibility with the copygb regridding utility mentioned in Section 3.3.
8.2.1. regrid_data_plane Usage
The usage statement for the regrid_data_plane utility is shown below:
Usage: regrid_data_plane
input_filename
to_grid
output_filename
-field string
[-method type]
[-width n]
[-gaussian_dx n]
[-gaussian_radius n]
[-shape type]
[-vld_thresh n]
[-name list]
[-log file]
[-v level]
[-compress level]
8.2.1.1. Required Arguments for regrid_data_plane
The input_filename is the gridded data file to be read.
The to_grid defines the output grid as a named grid, the path to a gridded data file, or an explicit grid specification string.
The output_filename is the output NetCDF file to be written.
The -field string may be used multiple times to define the field(s) to be regridded.
8.2.1.2. Optional Arguments for regrid_data_plane
The -method type option overrides the default regridding method. Default is NEAREST.
The -width n option overrides the default regridding width. Default is 1. In case of MAXGAUSS method, the width should be the ratio between from_grid and to_grid (for example, 27 if from_grid is 3km and to_grid is 81.271km).
The -gaussian_dx option overrides the default delta distance for Gaussian smoothing. Default is 81.271. Ignored if not the MAXGAUSS method.
The -gaussian_radius option overrides the default radius of influence for Gaussian interpolation. Default is 120. Ignored if not the MAXGAUSS method.
The -shape option overrides the default interpolation shape. Default is SQUARE.
The -vld_thresh n option overrides the default required ratio of valid data for regridding. Default is 0.5.
The -name list specifies a comma-separated list of output variable names for each field specified.
The -log file option directs output and errors to the specified log file. All messages will be written to that file as well as standard out and error. Thus, users can save the messages without having to redirect the output on the command line. The default behavior is no log file.
The -v level option indicates the desired level of verbosity. The contents of “level” will override the default setting of 2. Setting the verbosity to 0 will make the tool run with no log messages, while increasing the verbosity above 1 will increase the amount of logging.
The -compress level option specifies the desired level of compression (deflate level) for NetCDF variables. The valid level is between 0 and 9. Setting the compression level to 0 will make no compression for the NetCDF output. Lower number is for fast compression and higher number is for better compression.
For more details on setting the to_grid, -method, -width, and -vld_thresh options, see the regrid entry in Section 5. An example of the regrid_data_plane calling sequence is shown below:
regrid_data_plane \
input.grb \
togrid.grb \
regridded.nc \
-field 'name="APCP"; level="A6";'
-field 'name="TMP"; level="Z2";' \
-field 'name="UGRD"; level="Z10";' \
-field 'name="VGRD"; level="Z10";' \
-field 'name="HGT"; level="P500";' \
-method BILIN -width 2 -v 1
In this example, the Regrid-Data-Plane tool will regrid data from the input.grb file to the grid on which the first record of the togrid.grb file resides using Bilinear Interpolation with a width of 2 and write the output in NetCDF format to a file named regridded.nc. The variables in regridded.nc will include 6-hour accumulated precipitation, 2m temperature, 10m U and V components of the wind, and the 500mb geopotential height.
8.2.2. Automated Regridding within Tools
While the Regrid-Data-Plane tool is useful as a stand-alone tool, the capability is also included to automatically regrid one or both fields in most of the MET tools that handle gridded data. See the regrid entry in Section 4.5 for a description of the configuration file entries that control automated regridding.
8.3. Shift-Data-Plane Tool
The Shift-Data-Plane tool performs a rigid shift of the entire grid based on user-defined specifications and writes the field(s) out in NetCDF format. This tool was originally designed to account for track error when comparing fields associated with tropical cyclones. The user specifies the latitude and longitude of the source and destination points to define the shift. Both points must fall within the domain and are used to define the X and Y direction grid unit shift. The shift is then applied to all grid points. The user may specify the method of interpolation and the field to be shifted. The effects of topography and land/water masks are ignored.
8.3.1. shift_data_plane Usage
The usage statement for the shift_data_plane utility is shown below:
Usage: shift_data_plane
input_filename
output_filename
field_string
-from lat lon
-to lat lon
[-method type]
[-width n]
[-shape SHAPE]
[-log file]
[-v level]
[-compress level]
shift_data_plane has five required arguments and can also take optional ones.
8.3.1.1. Required Arguments for shift_data_plane
The input_filename is the gridded data file to be read.
The output_filename is the output NetCDF file to be written.
The field_string defines the data to be shifted from the input file.
The -from lat lon specifies the starting location within the domain to define the shift. Latitude and longitude are defined in degrees North and East, respectively.
The -to lat lon specifies the ending location within the domain to define the shift. Lat is deg N, Lon is deg E.
8.3.1.2. Optional Arguments for shift_data_plane
The -method type overrides the default regridding method. Default is NEAREST.
The -width n overrides the default regridding width. Default is 2.
The -shape SHAPE overrides the default interpolation shape. Default is SQUARE.
The -log file option directs output and errors to the specified log file. All messages will be written to that file as well as standard out and error. Thus, users can save the messages without having to redirect the output on the command line. The default behavior is no log file.
The -v level option indicates the desired level of verbosity. The contents of “level” will override the default setting of 2. Setting the verbosity to 0 will make the tool run with no log messages, while increasing the verbosity above 1 will increase the amount of logging.
The -compress level option indicates the desired level of compression (deflate level) for NetCDF variables. The valid level is between 0 and 9. The value of “level” will override the default setting of 0 from the configuration file or the environment variable MET_NC_COMPRESS. Setting the compression level to 0 will make no compression for the NetCDF output. Lower number is for fast compression and higher number is for better compression.
For more details on setting the -method and -width options, see the regrid entry in Section 5. An example of the shift_data_plane calling sequence is shown below:
shift_data_plane \
nam.grib \
nam_shift_APCP_12.nc \
'name = "APCP"; level = "A12";' \
-from 38.6272 -90.1978 \
-to 40.1717 -105.1092 \
-v 2
In this example, the Shift-Data-Plane tool reads 12-hour accumulated precipitation from the nam.grb file, applies a rigid shift defined by (38.6272, -90.1978) to (40.1717, -105.1092) and writes the output in NetCDF format to a file named nam_shift_APCP_12.nc. These -from and -to locations result in a grid shift of -108.30 units in the x-direction and 16.67 units in the y-direction.
8.4. MODIS regrid Tool
This section contains a description of running the MODIS regrid tool. This tool may be run to create a NetCDF file for use in other MET tools from MODIS level 2 cloud product from NASA.
8.4.1. modis_regrid Usage
The usage statement for the modis_regrid utility is shown below:
Usage: modis_regrid
-data_file path
-field name
-out path
-scale value
-offset value
-fill value
[-units text]
[-compress level]
modis_file
modis_regrid has some required arguments and can also take optional ones.
8.4.1.1. Required Arguments for modis_regrid
The -data_file path argument specifies the data files used to get the grid information.
The -field name argument specifies the name of the field to use in the MODIS data file.
The -out path argument specifies the name of the output NetCDF file.
The -scale value argument specifies the scale factor to be used on the raw MODIS values.
The -offset value argument specifies the offset value to be used on the raw MODIS values.
The -fill value argument specifies the bad data value in the MODIS data.
The modis_file argument is the name of the MODIS input file.
8.4.1.2. Optional Arguments for modis_regrid
The -units text option specifies the units string in the global attributes section of the output file.
The -compress level option indicates the desired level of compression (deflate level) for NetCDF variables. The valid level is between 0 and 9. The value of “level” will override the default setting of 0 from the configuration file or the environment variable MET_NC_COMPRESS. Setting the compression level to 0 will make no compression for the NetCDF output. Lower number is for fast compression and higher number is for better compression.
An example of the modis_regrid calling sequence is shown below:
modis_regrid -field Cloud_Fraction \
-data_file grid_file \
-out t2.nc \
-units percent \
-scale 0.01 \
-offset 0 \
-fill 127 \
modis_file
In this example, the Modis-Regrid tool will process the Cloud_Fraction field from modis_file and write it out to the output NetCDF file t2.nc on the grid specified in grid_file using the appropriate scale, offset and fill values.
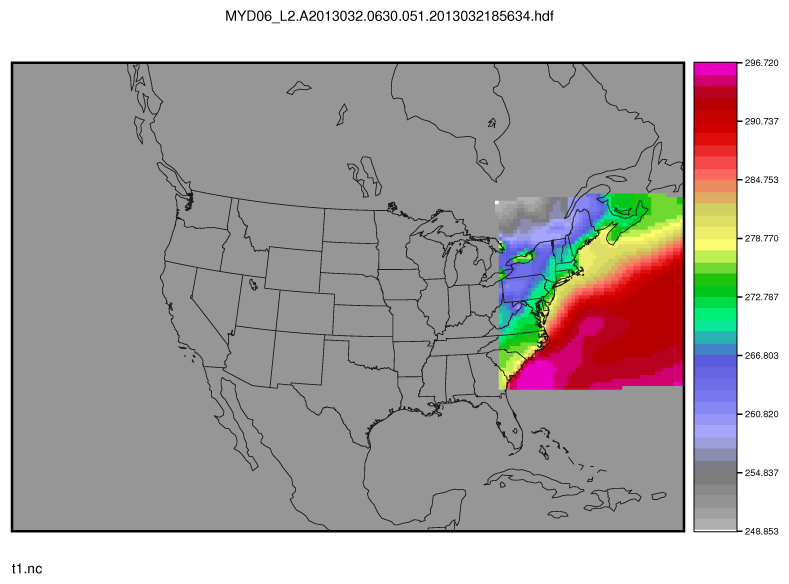
Figure 8.1 Example plot showing surface temperature from a MODIS file.
8.5. WWMCA Tool Documentation
There are two WWMCA tools available. The WWMCA-Plot tool makes a PostScript plot of one or more WWMCA cloud percent files and the WWMCA-Regrid tool regrids binary WWMCA data files and reformats them into NetCDF files that the other MET tools can read. The WWMCA-Regrid tool has been generalized to more broadly support any data stored in the WWMCA binary format.
The WWMCA tools attempt to parse timing and hemisphere information from the file names. They tokenize the filename using underscores (_) and dots (.) and examine each element which need be in no particular order. A string of 10 or more numbers is interpreted as the valid time in YYYYMMDDHH[MMSS] format. The string NH indicates the northern hemisphere while SH indicates the southern hemisphere. While WWMCA data is an analysis and has no forecast lead time, other datasets following this format may. Therefore, a string of 1 to 4 numbers is interpreted as the forecast lead time in hours. While parsing the filename provides default values for this timing information, they can be overridden by explicitly setting their values in the WWMCA-Regrid configuration file.
8.5.1. wwmca_plot Usage
The usage statement for the WWMCA-Plot tool is shown below:
Usage: wwmca_plot
[-outdir path]
[-max max_minutes]
[-log file]
[-v level]
wwmca_cloud_pct_file_list
wmmca_plot has some required arguments and can also take optional ones.
8.5.1.1. Required Arguments for wwmca_plot
The wwmca_cloud_pct_file_list argument represents one or more WWMCA cloud percent files given on the command line. As with any command given to a UNIX shell, the user can use meta-characters as a shorthand way to specify many filenames. For each input file specified, one output PostScript plot will be created.
8.5.1.2. Optional Arguments for wwmca_plot
The -outdir path option specifies the directory where the output PostScript plots will be placed. If not specified, then the plots will be put in the current (working) directory.
The -max minutes option specifies the maximum pixel age in minutes to be plotted.
The -log file option directs output and errors to the specified log file. All messages will be written to that file as well as standard out and error. Thus, users can save the messages without having to redirect the output on the command line. The default behavior is no log file.
The -v level option indicates the desired level of verbosity. The value of “level” will override the default setting of 2. Setting the verbosity to 0 will make the tool run with no log messages, while increasing the verbosity will increase the amount of logging.
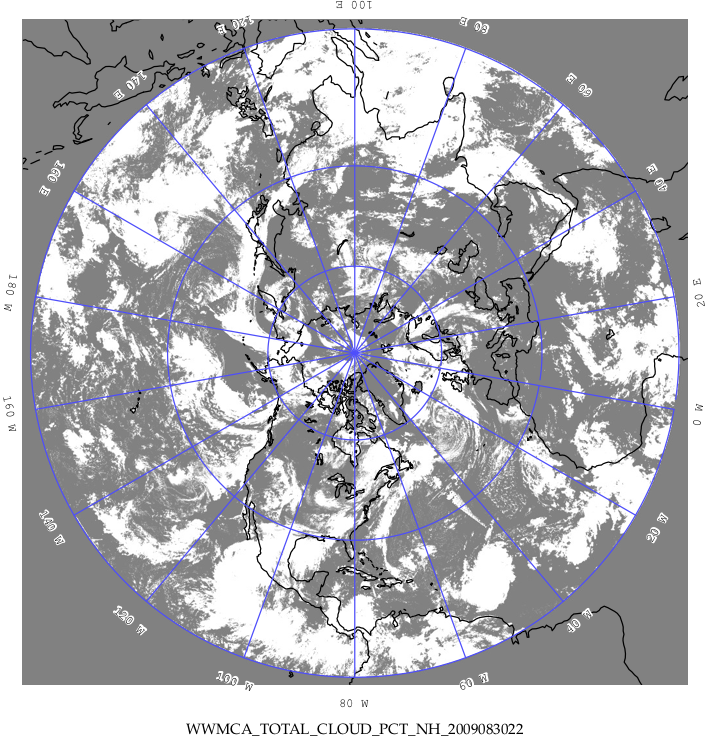
Figure 8.2 Example output of WWMCA-Plot tool.
8.5.2. wwmca_regrid Usage
The usage statement for the WWMCA-Regrid tool is shown below:
Usage: wwmca_regrid
-out filename
-config filename
-nh filename [pt_filename]
-sh filename [pt_filename]
[-log file]
[-v level]
[-compress level]
wmmca_regrid has some required arguments and can also take optional ones.
8.5.2.1. Required Arguments for wwmca_regrid
The -out filename argument specifies the name of the output netCDF file.
The -config filename argument indicates the name of the configuration file to be used. The contents of the configuration file are discussed below.
The -nh filename [pt_filename] argument specifies the northern hemisphere WWMCA binary file and, optionally, may be followed by a binary pixel age file. This switch is required if the output grid includes any portion of the northern hemisphere.
The -sh filename [pt_filename] argument specifies the southern hemisphere WWMCA binary file and, optionally, may be followed by a binary pixel age file. This switch is required if the output grid includes any portion of the southern hemisphere.
8.5.2.2. Optional Arguments for wwmca_regrid
The -log file option directs output and errors to the specified log file. All messages will be written to that file as well as standard out and error. Thus, users can save the messages without having to redirect the output on the command line. The default behavior is no log file.
The -v level option indicates the desired level of verbosity. The value of “level” will override the default setting of 2. Setting the verbosity to 0 will make the tool run with no log messages, while increasing the verbosity will increase the amount of logging.
The -compress level option indicates the desired level of compression (deflate level) for NetCDF variables. The valid level is between 0 and 9. The value of “level” will override the default setting of 0 from the configuration file or the environment variable MET_NC_COMPRESS. Setting the compression level to 0 will make no compression for the NetCDF output. Lower number is for fast compression and higher number is for better compression.
In any regridding problem, there are two grids involved: the “From” grid, which is the grid the input data are on, and the “To” grid, which is the grid the data are to be moved onto. In WWMCA-Regrid the “From” grid is pre-defined by the hemisphere of the WWMCA binary files being processed. The “To” grid and corresponding regridding logic are specified using the regrid section of the configuration file. If the “To” grid is entirely confined to one hemisphere, then only the WWMCA data file for that hemisphere needs to be given. If the “To” grid or the interpolation box used straddles the equator, the data files for both hemispheres need to be given. Once the “To” grid is specified in the config file, the WWMCA-Regrid tool will know which input data files it needs and will complain if it is not given the right ones.
8.5.3. wwmca_regrid Configuration File
The default configuration file for the WWMCA-Regrid tool named WWMCARegridConfig_default can be found in the installed share/met/config directory. We encourage users to make a copy of this file prior to modifying its contents. The contents of the configuration file are described in the subsections below.
Note that environment variables may be used when editing configuration files, as described in the Section 5.1.1.
regrid = { ... }
See the regrid entry in Section 4.5 for a description of the configuration file entries that control regridding.
variable_name = "Cloud_Pct";
units = "percent";
long_name = "cloud cover percent";
level = "SFC";
The settings listed above are strings which control the output netCDF variable name and specify attributes for that variable.
init_time = "";
valid_time = "";
accum_time = "01";
The settings listed above are strings which specify the timing information for the data being processed. The accumulation time is specified in HH[MMSS] format and, by default, is set to a value of 1 hour. The initialization and valid time strings are specified in YYYYMMDD[_HH[MMSS]] format. However, by default they are set to empty strings. If empty, the timing information parsed from the filename will be used. If not empty, these values override the times parsed from the filename.
max_minutes = 120;
swap_endian = TRUE;
write_pixel_age = FALSE;
The settings listed above control the processing of the WWMCA pixel age data. This data is stored in binary data files in 4-byte blocks. The swap_endian option indicates whether the endian-ness of the data should be swapped after reading. The max_minutes option specifies a maximum allowed age for the cloud data in minutes. Any data values older than this value are set to bad data in the output. The write_pixel_age option writes the pixel age data, in minutes, to the output file instead of the cloud data.