17. Series-Analysis Tool
17.1. Introduction
The Series-Analysis Tool accumulates statistics separately for each horizontal grid location over a series. Often, this series is over time or height, though any type of series is possible. This differs from the Grid-Stat tool in that Grid-Stat verifies all grid locations together as a group. Thus, the Series-Analysis Tool can be used to find verification information specific to certain locations or see how model performance varies over the domain.
17.2. Practical Information
This Series-Analysis tool performs verification of gridded model fields using matching gridded observation fields. It computes a variety of user-selected statistics. These statistics are a subset of those produced by the Grid-Stat tool, with options for statistic types, thresholds, and conditional verification options as discussed in Section 12. However, these statistics are computed separately for each grid location and accumulated over some series such as time or height, rather than accumulated over the whole domain for a single time or height as is done by Grid-Stat.
This tool computes statistics for exactly one series each time it is run. Multiple series may be processed by running the tool multiple times. The length of the series to be processed is determined by the first of the following that is greater than one: the number of forecast fields in the configuration file, the number of observation fields in the configuration file, the number of input forecast files, the number of input observation files. Several examples of defining series are described below.
To define a time series of forecasts where the valid time changes for each time step, set the forecast and observation fields in the configuration file to single values and pass the tool multiple forecast and observation files. The tool will loop over the forecast files, extract the specified field from each, and then search the observation files for a matching record with the same valid time.
To define a time series of forecasts that all have the same valid time, set the forecast and observation fields in the configuration file to single values. Pass the tool multiple forecast files and a single observation file containing the verifying observations. The tool will loop over the forecast files, extract the specified field from each, and then retrieve the verifying observations.
To define a series of vertical levels all contained in a single input file, set the forecast and observation fields to a list of the vertical levels to be used. Pass the tool single forecast and observation files containing the vertical level data. The tool will loop over the forecast field entries, extract that field from the input forecast file, and then search the observation file for a matching record.
17.2.1. series_analysis usage
The usage statement for the Series-Analysis tool is shown below:
Usage: series_analysis
-fcst file_1 ... file_n | fcst_file_list
-obs file_1 ... file_n | obs_file_list
[-both file_1 ... file_n | both_file_list]
[-paired]
-out file
-config file
[-log file]
[-v level]
[-compress level]
series_analysis has four required arguments and accepts several optional ones.
17.2.1.1. Required arguments series_stat
The -fcst file_1 … file_n | fcst_file_list options specify the gridded forecast files or ASCII files containing lists of file names to be used.
The -obs file_1 … file_n | obs_file_list are the gridded observation files or ASCII files containing lists of file names to be used.
The -out file is the NetCDF output file containing computed statistics.
The -config file is a Series-Analysis Configuration file containing the desired settings.
17.2.1.2. Optional arguments for series_analysis
To set both the forecast and observations to the same set of files, use the optional -both file_1 … file_n | both_file_list option to the same set of files. This is useful when reading the NetCDF matched pair output of the Grid-Stat tool which contains both forecast and observation data.
The -paired option indicates that the -fcst and -obs file lists are already paired, meaning there is a one-to-one correspondence between the files in those lists. This option affects how missing data is handled. When -paired is not used, missing or incomplete files result in a runtime error with no output file being created. When -paired is used, missing or incomplete files result in a warning with output being created using the available data.
The -log file outputs log messages to the specified file.
The -v level overrides the default level of logging (2).
The -compress level option indicates the desired level of compression (deflate level) for NetCDF variables. The valid level is between 0 and 9. The value of “level” will override the default setting of 0 from the configuration file or the environment variable MET_NC_COMPRESS. Setting the compression level to 0 will make no compression for the NetCDF output. Lower number is for fast compression and higher number is for better compression.
An example of the series_analysis calling sequence is shown below:
series_analysis \
-fcst myfcstfilelist.txt \
-obs myobsfilelist.txt \
-config SeriesAnalysisConfig \
-out out/my_series_statistics.nc
In this example, the Series-Analysis tool will process the list of forecast and observation files specified in the text file lists into statistics for each grid location using settings specified in the configuration file. Series-Analysis will create an output NetCDF file containing requested statistics.
17.2.2. series_analysis output
The Series-Analysis tool produces NetCDF files containing output statistics for each grid location from the input files. The details about the output statistics available from each output line type are detailed in Chapter 5 since they are also produced by the Grid-Stat Tool. A subset of these can be produced by this tool, with the most notable exceptions being the wind vector and neighborhood statistics. Users can inventory the contents of the Series-Analysis output files using the ncdump -h command to view header information. Additionally, ncview or the Plot-Data-Plane tool can be used to visualize the output. An example of Series-Analysis output is shown in Figure 17.1 below.
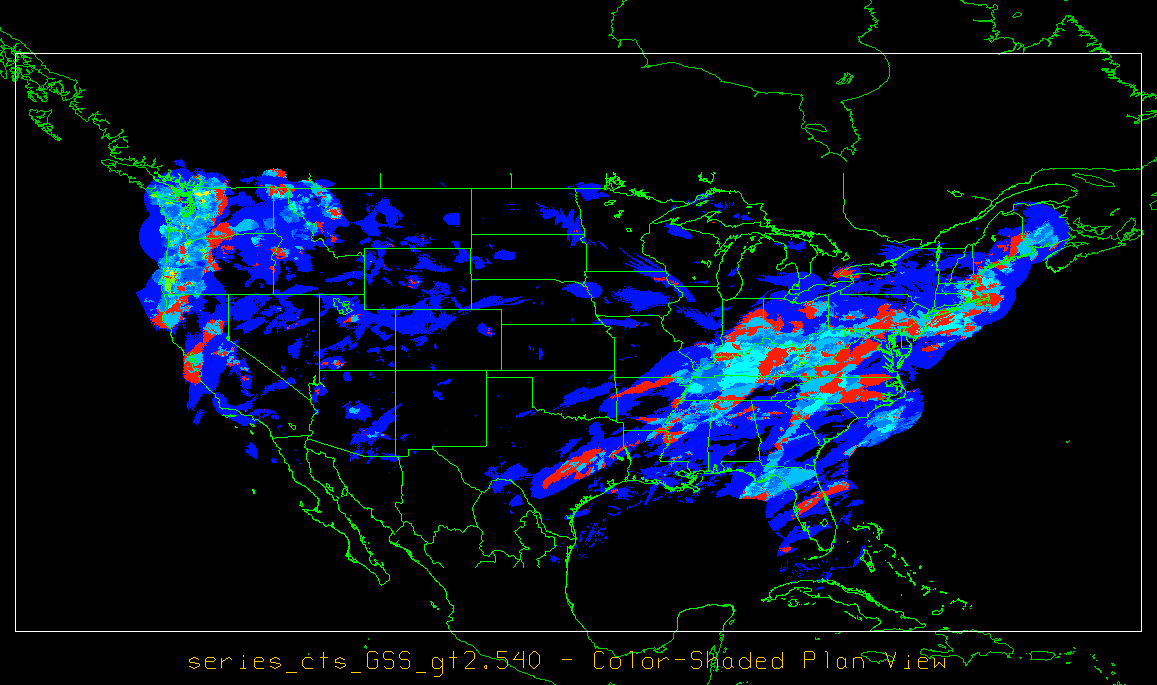
Figure 17.1 An example of the Gilbert Skill Score for precipitation forecasts at each grid location for a month of files.
17.2.3. series_analysis configuration file
The default configuration file for the Series-Analysis tool named SeriesAnalysisConfig_default can be found in the installed share/met/config directory. The contents of the configuration file are described in the subsections below.
Note that environment variables may be used when editing configuration files, as described in the Section 5.1.1.
model = "WRF";
desc = "NA";
obtype = "ANALYS";
regrid = { ... }
fcst = { ... }
obs = { ... }
climo_mean = { ... }
climo_stdev = { ... }
ci_alpha = [ 0.05 ];
boot = { interval = PCTILE; rep_prop = 1.0; n_rep = 1000;
rng = "mt19937"; seed = ""; }
mask = { grid = [ "FULL" ]; poly = []; }
hss_ec_value = NA;
rank_corr_flag = TRUE;
tmp_dir = "/tmp";
version = "VN.N";
The configuration options listed above are common to many MET tools and are described in Section 5.
block_size = 1024;
Number of grid points to be processed concurrently. Set smaller to use less memory but increase the number of passes through the data. The amount of memory the Series-Analysis tool consumes is determined by the size of the grid, the length of the series, and the block_size entry defined above. The larger this entry is set the faster the tool will run, subject to the amount of memory available on the machine. If set less than or equal to 0, it is automatically reset to the number of grid points, and they are all processed concurrently.
vld_thresh = 1.0;
Ratio of valid matched pairs for the series of values at each grid point required to compute statistics. Set to a lower proportion to allow some missing values. Setting it to 1.0 requires that every data point be valid over the series to compute statistics.
output_stats = {
fho = [];
ctc = [];
cts = [];
mctc = [];
mcts = [];
cnt = ["RMSE", "FBAR", "OBAR"];
sl1l2 = [];
sal1l2 = [];
pct = [];
pstd = [];
pjc = [];
prc = [];
}
The output_stats array controls the type of output that the Series-Analysis tool generates. Each flag corresponds to an output line type in the STAT file and is used to specify the comma-separated list of statistics to be computed. Use the column names from the tables listed below to specify the statistics. The output flags correspond to the following types of output line types:
FHO for Forecast, Hit, Observation Rates (See Table 11.2)
CTC for Contingency Table Counts (See Table 11.3)
CTS for Contingency Table Statistics (See Table 11.4)
MCTC for Multi-Category Contingency Table Counts (See Table 11.8)
MCTS for Multi-Category Contingency Table Statistics (See Table 11.9)
CNT for Continuous Statistics (See Table 11.6)
SL1L2 for Scalar L1L2 Partial Sums (See Table 11.15)
SAL1L2 for Scalar Anomaly L1L2 Partial Sums climatological data is supplied (See Table 11.16)
PCT for Contingency Table Counts for Probabilistic forecasts (See Table 11.10)
PSTD for Contingency Table Statistics for Probabilistic forecasts (See Table 11.11)
PJC for Joint and Conditional factorization for Probabilistic forecasts (See Table 11.12)
PRC for Receiver Operating Characteristic for Probabilistic forecasts (See Table 11.13)